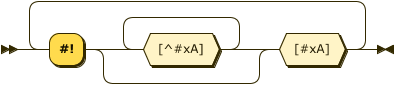Two-level Grammar of JinXML
Overview
JinXML has a whitespace insensitive layout, which means that it is a good idea to split the syntax into two phases: a lower-level tokenisation phase and an upper level parsing phase. This page describes both levels for JinXML in EBNF and also illustrates the grammars with railroad diagrams, thanks to the excellent Railroad Diagram Generator.
Upper-Level Grammar in EBNF, corresponds to parse phase
JinXML ::= Element | JSON | Call
Call ::= ( NCName | '&' ) '<' Attribute* ( '/>' | '>' '(' Item* ')' )
Element ::= StartTag Item* EndTag | FusedTag
StartTag ::= '<' Name Attribute* '>'
EndTag ::= '</' Name '>'
FusedTag ::= '<' Name Attribute* '/>'
Attribute ::= FieldPrefix String
JSON ::= Reserved | Number | String | Array | Object
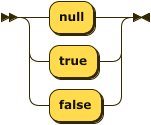
Reserved ::= 'null' | 'true' | 'false'
Item ::= ( Entry | JinXML ) Terminator?
Array ::= '[' ( JinXML Terminator? )* ']'
Object ::= '{' ( Entry Terminator? )* '}'
Entry ::= FieldPrefix JinXML
FieldPrefix ::= Name ( ':' | '=' | '+:' | '+=' )
Name ::= NCName | '&' | String
NCName ::= [http://www.w3.org/TR/xml-names/#NT-NCName]
Terminator ::= ',' | ';'
The following side-conditions apply:
- ElementNames in paired tags must not differ, where
&is considered to automatically match. &can only be used in a StartTag when its element appears on the right of an Entry.&can only be used as an Entry name when followed by a named StartTag (not&).
Top Level Grammar as Railroad Diagram
JinXML: JinXML is the non-terminal through which all recursion happens

Call: A function-call like syntax for elements

Element: Element are made up of tags

StartTag: Must be paired with an EndTag

EndTag: Must be paired with a StartTag

FusedTag: Combines a start-and-end tag pair when there are no children

Attribute: An attribute pairs up a name with a string value

JSON: Denotes a JSON-styled expression

Reserved: JSON reserves null, true and false

Array: JSON-style array brackets

Object: JSON-style object brackets

Entry: Member of JSON-style object

FieldPrefix: Member of JSON-style object
ElementName: Element names, attribute keys and object keys are almost identical - but ‘+’ is allowed for element names.

NCName: Same as XML spec

Terminator: Optional comma or semi between members of arrays, objects or elements.

Lower-Level Grammar for Tokenisation in EBNF, corresponds lexical analysis phase
Note that Shebang sequences may only occur at the start of a stream.
Reserved ::= 'null' | 'true' | 'false'
Number ::= '-'? [0-9]+ ( '.' [0-9]+ )? ( ( 'e' | 'E' ) [0-9]+ )?
String ::= SingleQuotedString | DoubleQuotedString
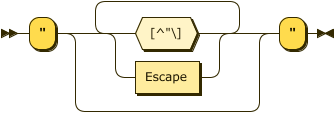
DoubleQuotedString ::= '"' ([^"\]|Escape)* '"'
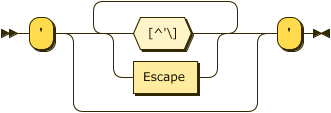
SingleQuotedString ::= "'" ([^'\]|Escape)* "'"
Escape ::= '\' ( ["'\/bfnrt] | 'u' Hex Hex Hex Hex | XEscape )
XEscape ::= '&' (NamedCharacterReference|'#' [0-9]+|'#x' Hex+)';'
NamedCharacterReference ::= [http://www.w3.org/TR/html5/syntax.html#named-character-references]
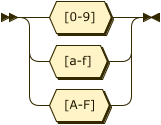
Hex ::= [0-9a-fA-F]
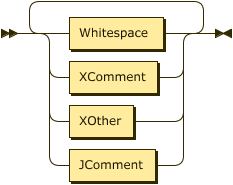
Discard ::= ( Whitespace | XComment | XOther | JComment )+
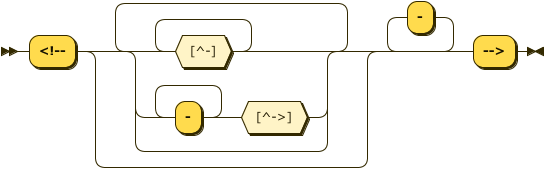
XComment ::= '<!--' ( [^-]* | '-'+ [^->] )* '-'* '-->'
XOther ::= '<' [?!] [^>]* '>'
JComment ::= LongComment | EoLComment
LongComment ::= '/*' ( [^*] | '*'+ [^*/] )* '*'* '*/'
EoLComment ::= '//' [^#xA]* #xA
Whitespace ::= (#x20 | #x9 | #xD | #xA)+
Shebang ::= ('#!' [^#xA]* #xA)+
Lower-Level Grammar for Tokenisation as Railroad Diagrams
Reserved: identifiers that play the role of literal constants
Numbers: Only base 10 so far

Strings: Single and double quoted strings and their symmetrical escape sequences

DoubleQuotedString: JSON-like double-quoted strings
SingleQuotedString: XML-like single-quoted strings
Escape: JSON-style Escapes

XEscape: XML-style Escapes
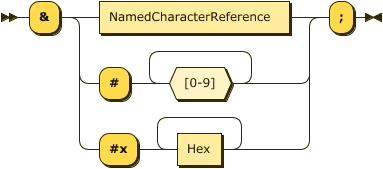
NamedCharacterReference:

Hex: Hex Characters
Discards: Tokens to be discarded
XComment: XML-style comment
XOther: Other XML-content to be discarded
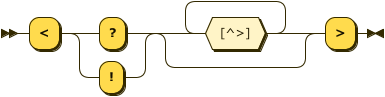
JComment: JSON-style comment

LongComment: Multi-line Javascript like comment
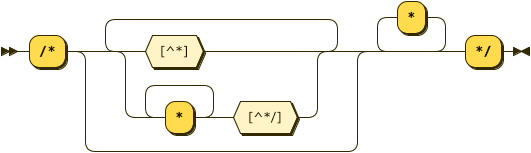
EoLComment: End of Line Javascript style comment

Whitespace:
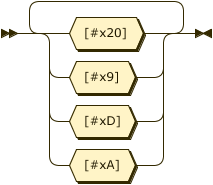
Shebang: